
The Memoptimized Rowstore enables high performance data streaming for applications, such as Internet of Things (IoT).
About the Memoptimized Rowstore
The Memoptimized Rowstore enables high performance data streaming for applications, such as Internet of Things (IoT) applications, which typically stream small amounts of data in single-row inserts from a large number of clients simultaneously and also query data for clients at a very high frequency.
The Memoptimized Rowstore provides the following functionality:
- Fast ingestFast ingest optimizes the processing of high-frequency, single-row data inserts into a database. Fast ingest uses the large pool for buffering the inserts before writing them to disk, so as to improve data insert performance.
- Fast lookupFast lookup enables fast retrieval of data from a database for high-frequency queries. Fast lookup uses a separate memory area in the SGA called the memoptimize pool for buffering the data queried from tables, so as to improve query performance.Note:For using fast lookup, you must allocate appropriate memory size to the memoptimize pool using the
MEMOPTIMIZE_POOL_SIZEinitialization parameter.
Using Fast Ingest
Fast ingest optimizes the processing of high-frequency, single-row data inserts into database from applications, such as Internet of Things (IoT) applications.
Fast ingest uses the MEMOPTIMIZE_WRITE hint to insert data into tables specified as MEMOPTIMIZE FOR WRITE. The database temporarily buffers these inserts in the large pool and automatically commits the changes at the time of writing these buffered inserts to disk. The changes cannot be rolled back.
The inserts using fast ingest are also known as deferred inserts, because they are initially buffered in the large pool and later written to disk asynchronously by background processes.
Steps for using fast ingest for inserting data into a table
The following are the steps for using fast ingest for inserting data into a table:
- Enable a table for fast ingest by specifying the
MEMOPTIMIZE FOR WRITEclause in theCREATE TABLEorALTER TABLEstatement.CopySQL> create table test_fast_ingest ( id number primary key, test_col varchar2(15)) segment creation immediate memoptimize for write; Table created.See “Enabling a Table for Fast Ingest” for more information. - Enable fast ingest for inserts by specifying the
MEMOPTIMIZE_WRITEhint in theINSERTstatement.The following is not how fast ingest is meant to be used, but demonstrates the mechanism.CopySQL> insert /*+ memoptimize_write */ into test_fast_ingest values (1, 'test'); 1 row created SQL> insert /*+ memotimize_write */ into test_fast_ingest values (2, 'test'); 1 row createdSee “Specifying a Hint for Using Fast Ingest for Data Inserts” for more information.
The result of the two inserts above is to write data to the ingest buffer in the large pool of the SGA. At some point, that data is flushed to the TEST_FAST_INGEST table. Until that happens, the data is not durable.
Because the purpose of fast-ingest is to support high performance data streaming, a more realistic architecture would involve having one or more application or ingest servers collecting data and batching inserts to the database.
The first time an insert is run, the fast ingest area is allocated from the large pool. The amount of memory allocated is written to the alert.log.
CopyMemoptimize Write allocated 2055M from large pool
If the request fails to allocate even the minimal memory requirement, then an error message is written to the alert.log.
CopyMemoptimize Write disabled. Unable to allocate sufficient memory from large pool.
Details about Fast Ingest
The intent of fast-ingest is to support applications that generate lots of informational data that has important value in the aggregate but that doesn’t necessarily require full ACID guarantees. Many applications in the Internet of Things (IoT) have a rapid “fire and forget” type workload, such as sensor data, smart meter data or even traffic cameras. For these applications, data might be collected and written to the database in high volumes for later analysis.
The following diagram shows how this might work with the Memoptimized Rowstore – Fast Ingest feature.
Figure 12-1 Fast-Ingest with high-frequency inserts.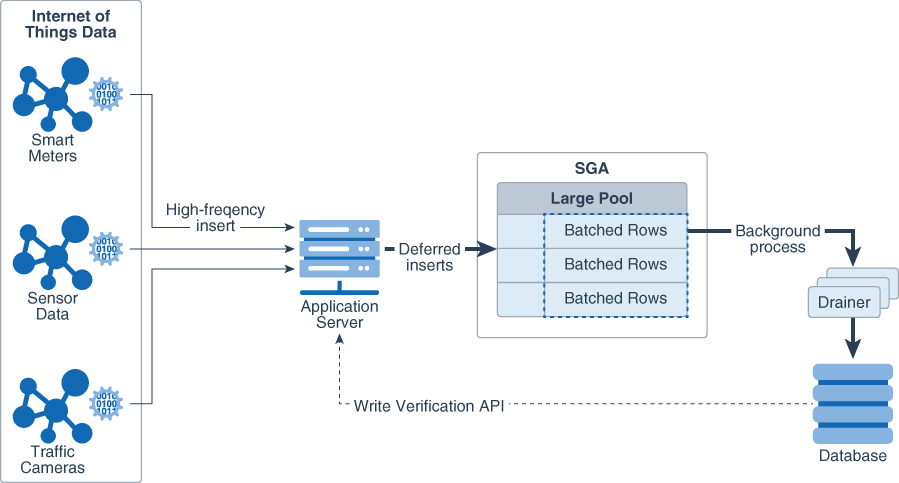
Description of “Figure 12-1 Fast-Ingest with high-frequency inserts.”
The ingested data is batched in the large pool and is not immediately written to the database. Thus, the ingest process is very fast. Very large volumes of data can be ingested efficiently without having to process individual rows. However, if the database goes down before the ingested data is written out to the database files, it is possible to lose data.
Fast ingest is very different from normal Oracle Database transaction processing where data is logged and never lost once “written” to the database (i.e. committed). In order to achieve the maximum ingest throughput, the normal Oracle transaction mechanisms are bypassed, and it is the responsibility of the application to check to see that all data was indeed written to the database. Special APIs have been added that can be called to check if the data has been written to the database.
The commit operation has no meaning in the context of fast ingest, because it is not a transaction in the traditional Oracle sense. There is no ability to rollback the inserts. You also cannot query the data until it has been flushed from the fast ingest buffers to disk. You can see some administrative information about the fast ingest buffers by querying the view V$MEMOPTIMIZE_WRITE_AREA.
You can also use the packages DBMS_MEMOPTIMIZE and DBMS_MEMOPTIMIZE_ADMIN to perform functions like flushing fast ingest data from the large pool and determining the sequence id of data that has been flushed.
Index operations and constraint checking is done only when the data is written from the fast ingest area in the large pool to disk. If primary key violations occur when the background processes write data to disk, then the database will not write those rows to the database.
Assuming (for most applications but not all) that all inserted data needs to be written to the database, it is critical that the application insert process checks to see that the inserted data has actually been written to the database before destroying that data. Only when that confirmation has occurred can the data be deleted from the inserting process.
Prerequisites for Fast Ingest Table
Fast Ingest is not supported for tables with certain characteristics, objects, or partitioning.
When the Autonomous Database supports an item and does not have that limitation, it is so noted.
- Tables with the following characteristics cannot use fast ingest:
- disk compression
- in-memory compression
- function-based indexes
- domain indexes
- bitmap indexes
- bitmap join indexes
- ref types
- varray types
- OID$ types
- unused columns
- LOBs
- triggers
- binary columns
- foreign keys
- row archival
- invisible columns [Autonomous Database supports virtual columns.]
- The following objects cannot use fast ingest.
- Temporary tables
- Nested tables
- Index organized tables
- External tables
- Materialized views with on-demand refresh
- Sub-partitioning is not supported. [Autonomous Database supports sub-partitioning.]
- The following partitioning types are not supported.
- REFERENCE
- SYSTEM
- INTERVAL [Autonomous Database supports this.]
- AUTOLIST [Autonomous Database supports this.]
The following are some additional considerations for fast ingest:
- Assuming (for most applications but not all) that all inserted data needs to be written to the database, it is critical that the application implement process checks to see that the inserted data has actually been written to the database before destroying that data. Only when that confirmation has occurred can the data be deleted from the inserting process.
- Because fast ingest buffers data in the large pool, there is a possibility of data loss in the event of a system failure. To avoid data loss, a client must keep a local copy of the data after performing inserts, so that it can replay the inserts in the event of a system failure before the data is written to disk. A client can use the
DBMS_MEMOPTIMIZEpackage subprograms to track the durability of the inserts. After inserts are written to disk, a client can destroy its local copy of the inserted data. - Queries do not read data from the large pool, hence data inserted using fast ingest cannot be queried until it is written to disk.
- Index operations are supported by fast ingest similar to the regular inserts. However, for fast ingest, database performs index operations while writing data to disk, and not while writing data into the large pool.
- The size allocated to the fast ingest buffers in the Large pool is fixed once created. If the buffer fills, further ingest waits until the background processes drain the buffer.
Note:
A table can be configured for using both fast ingest and fast lookup.
Enabling a Table for Fast Ingest
You can enable a table for fast ingest by specifying the MEMOPTIMIZE FOR WRITE clause in the CREATE TABLE or ALTER TABLE statement.
To enable a table for fast ingest:
- In SQL*Plus, log in to the database as a user with
ALTER TABLEprivileges. - Run the
CREATE TABLEorALTER TABLEstatement with theMEMOPTIMIZE FOR WRITEclause.The following example creates a new tabletest_fast_ingestand enables it for fast ingest:CopyCREATE TABLE test_fast_ingest ( id NUMBER(5) PRIMARY KEY, test_col VARCHAR2(15)) SEGMENT CREATION IMMEDIATE MEMOPTIMIZE FOR WRITE;The following example enables the existing tablehr.employeesfor fast ingest:CopyALTER TABLE hr.employees MEMOPTIMIZE FOR WRITE;
Specifying a Hint for Using Fast Ingest for Data Inserts
You can use fast ingest for data inserts by specifying the MEMOPTIMIZE_WRITE hint in INSERT statements.
Prerequisites
This task assumes:
- The table is already enabled for fast ingest.
- The optimizer is allowed to use hints, meaning
optimizer_ignore_hints=FALSE.
To use fast ingest for data inserts:
- In SQL*Plus, log in to the database as a user with the privileges to insert data into tables.
- Run the
INSERTstatement with theMEMOPTIMIZE_WRITEhint for a table that is already enabled for fast ingest.For example:CopyINSERT /*+ MEMOPTIMIZE_WRITE */ INTO test_fast_ingest VALUES (1,'test');
Disabling a Table for Fast Ingest
You can disable a table for fast ingest by specifying the NO MEMOPTIMIZE FOR WRITE clause in the ALTER TABLE statement.
To disable a table for fast ingest:
- In SQL*Plus, log in to the database as a user with the
ALTER TABLEprivileges. - Run the
ALTER TABLEstatement with theNO MEMOPTIMIZE FOR WRITEclause.The following example disables the tablehr.employeesfor fast ingest:CopyALTER TABLE hr.employees NO MEMOPTIMIZE FOR WRITE;
Managing Fast Ingest Data in the Large Pool
You can view the fast ingest data in the large pool using the V$MEMOPTIMIZE_WRITE_AREA view. You can also view and control the fast ingest data in the large pool using the subprograms of the packages DBMS_MEMOPTIMIZE and DBMS_MEMOPTIMIZE_ADMIN.
Overview of the V$MEMOPTIMIZE_WRITE_AREA view
The V$MEMOPTIMIZE_WRITE_AREA view provides the following information about the memory usage and data inserts in the large pool by fast ingest:
- Total amount of memory allocated for fast ingest data in the large pool
- Total amount of memory currently used by fast ingest data in the large pool
- Total amount of memory currently free for storing fast ingest data in the large pool
- Number of fast ingest insert operations for which data is still in the large pool and is yet to be written to disk
- Number of clients currently using fast ingest for inserting data into the database
credit: link