Release after release PostgreSQL is better and better on table partitioning, if you do run a version12 or 13 today you must have a look on this functionality. You don’t have to, but if you deal with big table and have some performance issues, it could be a solution for you. As always with PostgreSQL the quality start point is the official documentation https://www.postgresql.org/docs/current/ddl-partitioning.html.
This article is not to discuss advantage or disadvantage of partitioning a table, it’s goal is to show you how to do it. In most cases you’ll have to partition a table on a live applications with data in a simple table. I’ll give you here a way to partition this table without stopping your application, this will be done in live with real activity on the legacy table.
This it not the only one method to partition an existing table, the main advantage from my point of view it minimizes the LOCK, you could create a new table, fill it with the old data and change it’s name at the end, but you’ll have much more LOCK, your application will slow down or be stuck for minutes or hours depending of your amount of data. Personnaly I prefer to avoid LOCK on my production databases.
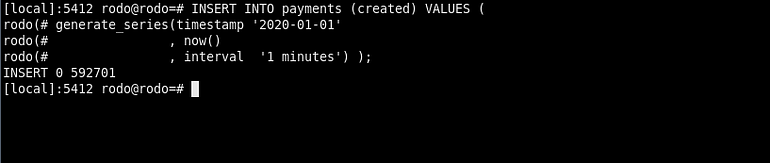
First of all, I nee a table with some data in it. All the command are available in a public repo on Github.
I use a simple table with 5 columns to store payments, with an amount, a status and some technical date.
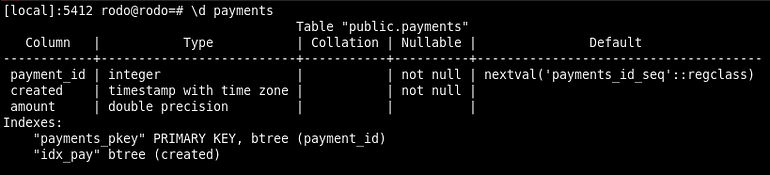
This article is wrote mid February, this is important as we will partition by date as you will see. So I fill my table with one payment per minute to obtain around 500k rows.
You can create the same table with the source file historic-table.sql
It’s not possible to transform a regular table into a partitioned one, and it’s possible to attach regular table to a partitioned one, this is what we will do in 4 steps.
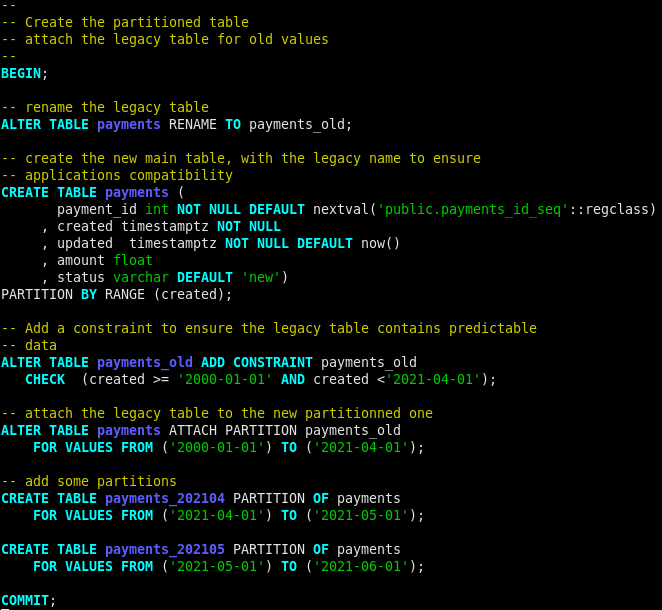
source partition.sql
Let’s comment a little bit the above screenshot.
First of all we rename the legacy table, remember we do this live and the application still read and write data from the table payments.
Second we create a new partitioned table we will called payments. We partition it by the column created, this is an arbitrary choice for this article. Note here that we reuse our sequence payments_id_seq
The third step is not mandatory, I added here a check to ensure that the table contains predictable data, I know there is no older data than January first 2020 (my lower bound), and we are in February 2021 so I use April first as upper bound (I manipulate data so I take wider than needed in case of … anything). If the check fails the transaction will rollback and nothing will happen, if you’re not aware of PostgreSQL you have to know tabout its ability to perform transactional DDL.
The last and maybe the most important action comes in fourth, with the attachment of the legacy table as a partition. You notice here the VALUES I use as bounds for this partition, they are the same of the check.
To be safe (again) I add two new partitions for the two following months.
Let’s have a look at what we have now.
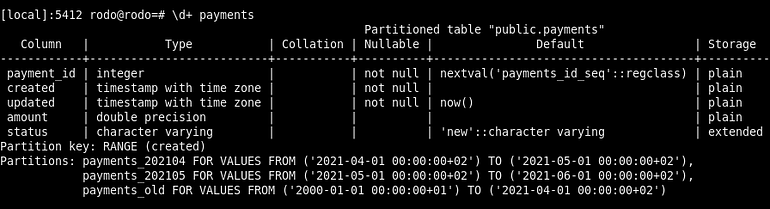
Yes we are, our new payments table contains 3 partitions, and if we look at the data they are still in a single table so we still have job todo. The payments_old contains 34 MB that is the size of all the data.

We can still stay as is and wait April to see data going in the dedicated table, we can do it better.
Second part, let’s move the historical data to a new partition. I’ll do it in two steps, the first will be on the data for March, why I do this, we are in February so we don’t have any payments created in march, always for the same reason, for safety ! We manipulate data we have to test and improve our actions before doing any action that may be a disaster.
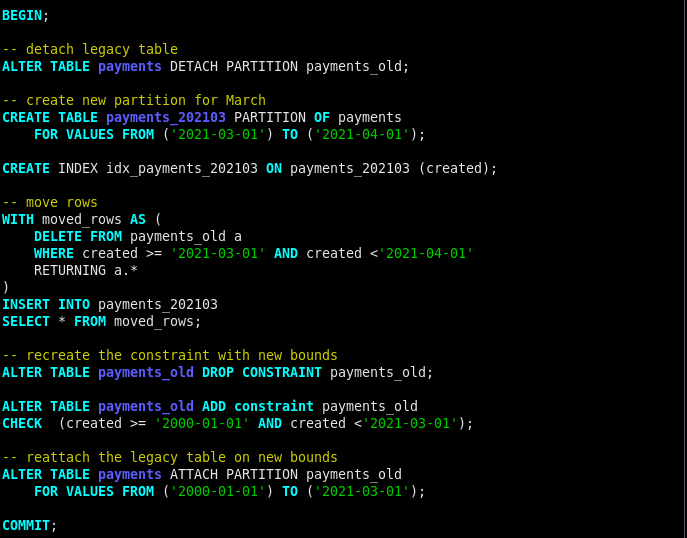
We start by detaching the historical table, we do this because we will change the bounds of the partition, now the historical partition won’t store data form March anymore.
Second we create the new partition, as we do previously and with bounds suitable for March. And add an index on it by the way.
Third, the dangerous one, we move rows from one table to the new one. But if you followed closely you know there is no data, here we just do the exercise to validate our process.
We do recheck our data by dropping and adding the constraints with right values.
And finally we reattach the historical table. We’re done !
source file split-march.sql
If you do the same with February with the source file split-feb.sql , now we will move data.
Let’s have a look if we search for payments between February 5th and 7th, we see that now our table payments is partitioned as the EXPLAIN command show it.
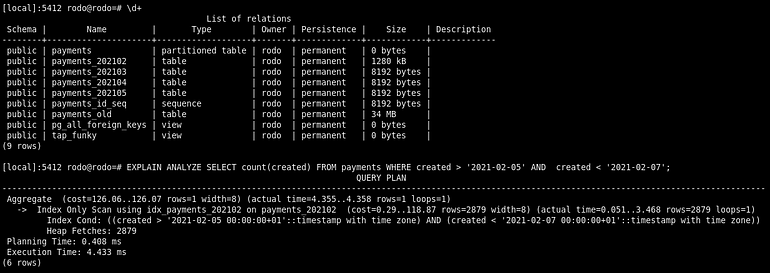
You know have a method to partition an historic table with data, and in live.
PS : if you want to improve the method with real activity on the database you can use the tsung’s scenario I wrote https://github.com/rodo/articles/blob/main/medium-pg-partition/application.xml
reference:https://rodoq.medium.com/partition-an-existing-table-on-postgresql-480b84582e8d