The ultimate goal for any unplanned database interruption is to reduce data loss.
Backups: The Most Important Thing
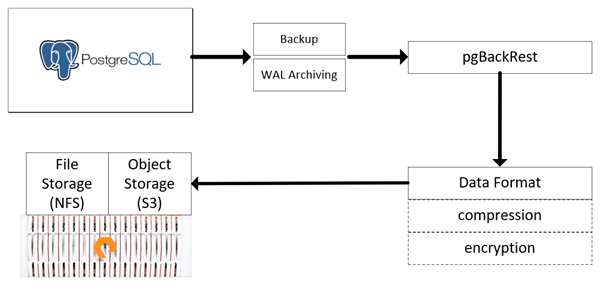
The most important thing that you can do for any database system is to have backups. Backups allow you to recover from a variety of scenarios and provide a safety net for when you run out-of-disk. Here pgBackRest, which provides a way to create a managed backup repository for PostgreSQL with a lot of settings for efficiency and safety.
When deploying a Postgres cluster into production, you should always have a backup strategy in place. This includes evaluating the following:
- Where your backups will live. Ensure they are on a different disk than your Postgres database, or in an blob object storage system like S3.
- What your backup retention policy is. It is typical to keep backups for 7 to 21 days. A phased backup approach is also wise. For example, you have a daily backup for 2 weeks, then you have 1 backup every 2 weeks up to 6 months, then 1 monthly backup for the last 3 years.
- How often to take backups. This will coincide with your RPO / RTO.
- How you monitor your backups. You want to ensure your backup repository is healthy in case you need to use it in a disaster scenario!
- Regularly testing your backups and doing test restores.
Having a healthy backup system provides more help in recovering from errors such as out-of-disk.
Full Disk
If Postgres has run out of disk space, there are a few things to look for. Depending on the server configuration there may be several devices at play, so your data directory, tablespaces, logs, or WAL directory could each be affected.
There are many reasons your disk might be full, here are some of the common ones to look for:
- The archive_command is failing and WAL is filling up the disk space.
- There are replication slots for a disconnected standby which results in WAL filling up the disk.
- Large database changes generate so much WAL that it consumes all of the available disk space.
- You literally just ran out of disk space storing data and your normal monitors and alerts didn’t let you know.
The situation that is most detrimental to the database system as a whole is a full WAL directory. This results in the database being unable to make any more changes to the database system because it can’t record the WAL changes. Then Postgres has no choice but to issue a PANIC and shut down.
As you can see, many of these cases relate to WAL filling the disk. Having the database shut down will land you in a precarious situation, so that’s where we’ll dig in with this post.
A Brief Overview of How Postgres WAL Archiving Works:
- When Postgres needs to make a change to data, it first records this change in the Write-Ahead-Log (WAL) and fsyncs the WAL to the disk. Fsync is a system call that guarantees that the data that was written has actually been written fully to persistent storage, not just stored in the filesystem cache. Once this WAL has been successfully written to disk, even if the database crashes between this write and the actual change to the data directory the database will be able to recover to a consistent state by replaying changes stored in the WAL.
- At some future point, the database will issue a CHECKPOINT, which flushes all of the modified buffers to disk and stores the changes permanently in the data directory. When a CHECKPOINT has been completed, the database records the WAL position at which this occurs and knows that all of this data up to this point has been successfully written to disk. (It is worth noting that any changes that are written to disk via the CHECKPOINT already had their contents recorded previously in the WAL stream, so this is just a way of ensuring that the changes recorded by the WAL data are in fact applied to the actual on-disk relation files.)
- WAL is stored in on-disk files in 16MB chunks; as the database generates WAL files, it runs the archive_command on them to handle storing these outside of the database. The archive_command’s exit code will determine whether Postgres considers this to have succeeded or not. Once the archive_command completes successfully, Postgres considers the WAL segment to have been successfully handled and can remove it or recycle it to conserve space. If the archive_command fails, Postgres keeps the WAL file around and tries again indefinitely until this command succeeds. Even if a particular segment file is failing, Postgres will continue to accumulate WAL files for all additional database changes and continue retrying to archive the previous file in the background.
As you can see, if there is an issue with the archive_command, this can lead up to a build-up in WAL, since Postgres will not remove any segments until they have been confirmed to be received by the archive_command.
When the Postgres server starts up, it will look at the pg_control file to determine when the last checkpoint was, and will replay all WAL that was generated in the database since the last checkpoint. This ensures that the database will reach a consistent state that will reflect all data changes made and recorded in the WAL.
WAL files are named sequentially, with multiple portions of the filename defined based on the ordering of changes made in the database. You can think of the entirety of the history of the database’s changes as made from playing all of the WAL files from the very beginning. However since over time there would be too many changes to replay, Postgres uses CHECKPOINTs as basically a point to determine that it is safe to remove/recycle WAL files and pick up from this point.
Just like a failing archivecommand can keep WAL files around indefinitely, a replication slot that is not getting updated due to the replication slot consumer being offline will prevent WAL from being removed and be a vector for filling up the disk. PostgreSQL 13 onward can protect against this specific scenario by using the max_slot_wal_keep_size setting. This has the benefit of limiting the amount of disk that will ever be taken up by WAL (thus preventing the primary server from shutting down due to insufficient storage), with the tradeoff that if you _do hit this limit, the replica will need to be rebuilt since the primary would have already removed the WAL needed for it to progress.
Broken Archives
A common case is that an issue arises with the archive_command returning an error. If this is insufficiently monitored, you can continue for quite some time with pgBackRest returning an error, and eventually the pg_wal directory fills up.
The archive_command can fail for different reasons; it could be out of disk space on the pgBackRest repository, ssh keys could have been changed, the pgBackRest version could have been updated on the repository server without a corresponding update on the primary database server, or many other possibilities. The only thing to do here is to ensure that you are monitoring your logs in particular for archive_command failures, as this will generally indicate an issue that must be resolved by your DBA team.
When the pg_wal disk filled up, this meant that there was no more space to write additional changes, so Postgres did the only thing it could: it panicked and terminated the server and all connections; there is not much use for a database which cannot make any more changes.
It is important to keep in mind that even if Postgres has shut down due to a full pg_wal disk and will not start up again, you don’t have a corrupted database at this point. You will still be able to take some actions to bring the database up without losing or corrupting data.
What NOT to do:
- Never remove WAL.
A common knee jerk reaction to seeing WAL filling up your disk space is to delete these log files. This is a very common approach by system administrators – big log files fill up the disk, get rid of them, right? But … wait …. WAL are not just normal system logs. They’re integral to getting your Postgres up and running, remember the checkpoints above? Removing WAL WILL CORRUPT YOUR DATABASE.
Remember, Postgres itself will remove the extra WAL files as soon as it is operating correctly and it has verified that it will not need those files any more (i.e., it confirms it has archived the files successfully).
If you remove WAL files, you are guaranteed that your database will be in an inconsistent state and it will be corrupted. NEVER REMOVE WAL FILES!
The only time to remove WAL is under specific instruction and direction from experts. Do we ever remove WAL files and copy them elsewhere? Of course, yes, we do. But this is in an expert situation, where we’ve taken backups of the system, and can rollback to a known state as needed.
- Don’t immediately overwrite the existing data directory with a restore from a backup.
In the best case when you restore from a backup, you have determined that you are okay with data loss, as you are effectively choosing to forgo any database changes since the last backup. Restoring from a backup is a disaster recovery approach that is generally meant to be helpful in a situation where the entire system is inoperable or the data files have been corrupted; i.e., true disasters.
In particular, if you have an archivecommand that was failing, this means you are giving up all transactions that occurred in the database since the last successful backup. And this is key: if the archive_command is failing, and that is what you are using for your base backups as well, there is no guarantee of the age of the last backup. (You _are monitoring your backups and archive_commands, right?)
Backup restoration can be done if needed, but this should not be where you first go when you discover an issue.
- Don’t just resize in place.
As production is down, you’ll obviously be keen to get this fixed ASAP. While your knee-jerk reaction to running out of disk will be to add more storage, it can often be better to provision a new larger instance and work on restoration there, rather than trying to resize in place. First and most importantly, we want to keep the broken instance in place so we can refer to it later; at this point it may be unclear as to what the true cause of the issue is. Preserving any production instance that has stopped working is the best way to perform post-mortem analysis and have confidence in the integrity of any newly working system.
Note: This is a softer “don’t” than the others; if this is your only option for getting the database up and running, this approach should work fine.
What you SHOULD do:
- Take a filesystem-level backup right now.
Ensure that Postgres is stopped and take a backup of the PostgreSQL data directory (including the pg_wal directory and any non-default tablespaces) before you do anything so you can get back to this state if you need to. There are a dozen different things that can go wrong in fixing Postgres and your WAL archive, so being able to preserve as much of the original evidence/state will both protect you in the rebuild process, as well as provide valuable forensic data for determining root causes.
Any method of handling this is possible; for instance pgBackRest supports an offline backup, you can use filesystem-level snapshots, rsync to a remote server, tarball, etc.
- Create a new instance (or at least a new volume) with sufficient space.
We recommend doing restores to a new instance whenever possible. If you are able to use the backup you just created, you can test starting this up after making sure that all of the configuration, paths, etc are correct on the new instance. If you are installing on a new instance, also make sure that you are using the same Postgres version (including other packages and extensions), and that the locale has the same setting.
Now that you’ve eliminated the space issues, you should be able to resume database operations.
- Fix the underlying issues.
Now that the database is back up and running, review the logs for why this failed, and fix the underlying issues. Now add/adjust your monitoring so you will be able to detect and prevent this issue in the future. For instance, if this was caused by a failing archive_command, you can utilize some log analysis tools to notify you if such a thing starts happening again. pgMonitor can detect a failing archive_command, as well as alert when disk percentages reach a certain threshold.
To summarize here, if there’s one thing you take away, do not delete your WAL. If your disk is filling up, Postgres has tools to help you recover quickly and efficiently.
credit: https://www.crunchydata.com/blog/postgres-is-out-of-disk-and-how-to-recover-the-dos-and-donts